문자열을 토큰으로 나누기 위해 사용되며, 구분자는 생성시 설정할 수 있습니다.
간단히 생성하고 사용하는 방법은 다음 예제를 통해 보실 수 있습니다.
StringTokenizer stk = new StringTokenizer("this is test");
while (stk.hasMoreTokens()) {
System.out.println(stk.nextToken());
}
this
is
test
public StringTokenizer(String str) {
this(str, " \t\n\r\f", false);
}
문자열, 구분자, flag 순으로 입력받으며 문자열은 필수이고 나머지는 default가 따로 있습니다.
public StringTokenizer(String str, String delim) {
this(str, delim, false);
}
public StringTokenizer(String str, String delim, boolean returnDelims){
currentPosition = 0;
newPosition = -1;
delimsChanged = false;
this.str = str;
maxPosition = str.length();
delimiters = delim;
retDelims = returnDelims;
setMaxDelimCodePoint();
}
flag의 값에 따른 차이
StringTokenizer stk = new StringTokenizer("apple/banana/pear","/",true);
while (stk.hasMoreTokens()) {
System.out.println(stk.nextToken());
}
apple
/
banana
/
pear
이렇게 구분자로 사용한 “/” 또한 하나의 토큰이 되어 출력됩니다.
| Return | Method | Desrption |
|---|---|---|
| int | countTokens() | 현재 남아있는 토큰 수 반환 |
| boolean | hasMoreTokens() | 토큰이 남아있다면 true, 없다면 false |
| boolean | hasMoreElements() | hasMoreTokens()와 동일 |
| String | nextToken() | 토큰을 읽어오며, 수행 시 읽어온 토큰은 빠진다 |
| String | nextElement() | nextToken()와 동일 |
둘은 문자열 구분에 있어서 결과적으로도 속도적으로도 차이가 있습니다.
public String[] split(String regex, int limit)
split은 입력 받은 정규식을 이용해 문자열을 분리해 배열을 리턴합니다. 정규식을 이용한 분리를 이용하기 때문에 속도 면에서 StringTokenizer 보다 느립니다.
하지만 좀 더 구체적이고 유연한 구분이 가능합니다.
public class StringTokenizer implements Enumeration<Object>
StringTokenizer는 Enumeration을 구현하는 클래스로 문자열을 배열로 접근하기 보단 구분자로 구분해 입력 받을 때 사용할 때 적절합니다.
구분자를 하나밖에 이용할 수 없고 비교적 정확도가 떨어집니다.
split은 유연하고 구체적인 구분을 위해 사용하는 것이 좋으며, StringTokenizer는 비교적 단순한 구분과 나은 속도 성능을 필요로 할 때 사용하는 것이 좋다.
예시 문자열이 다음과 같을 때, 구분자를 “/&”으로 했습니다.
String test = "apple/&banana/chicken&/";
StringTokenizer stk = new StringTokenizer(test,"/&");
String[] splitArr = test.split("/&");
StringTokenizer============
apple
banana
chicken
split============
apple
banana/chicken&/
출력은 위처럼 다르게 나타납니다.
우선 StringTokenizer의 경우 구분자 중의 하나만 포함해도 구분자로 인식합니다.
split은 정확히 같아야 구분자로 인식됩니다.
예시 문자열이 다음과 같을 때, 구분자를 “*“으로 했습니다.
String test = "apple/*banana/chicken*/";
StringTokenizer stk = new StringTokenizer(test,"*");
String[] splitArr = test.split("*");
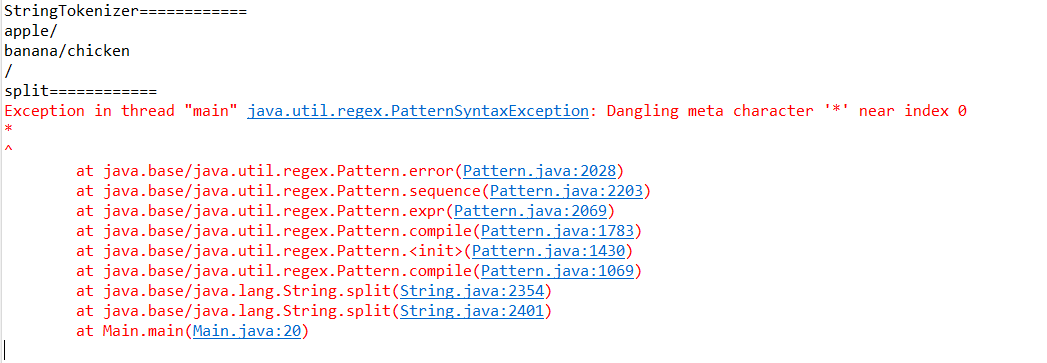
위처럼 되는 이유는 *이 정규식에서 특별한 의미를 가지는 메타 문자이기 때문입니다.
split에서 특정 문자는 단독으로 사용될 수 없습니다. 그 종류는 다음과 같습니다.
.$|()[{^?*+\\ 이 문자들을 split에서 구분자로 사용하기 위해선 \\(역슬래쉬 두 번)을 앞에 붙여주어야 합니다.
String[] splitArr = test.split("\\*");
이렇게요!
특수한 경우의 예시만 간단히 가져왔습니다.
눈에 보이진 않지만 속도 차이가 좀 나긴 하는 것 같습니다.
백준 알고리즘 문제를 풀다가 시간 초과 문제가 발생해서 질문 검색의 비슷한 경우의 답변을 봤는데, split을 StringTokenizer로 고쳐 해결했다고 해서 해봤는데 저도 도움이 되어 비교해 조사해 보았습니다.
참조
감사합니다.
Text by Chaelin. Photographs by Chaelin, Unsplash.